델파이 XE4 버전에서는 iOS 및 ARM 컴파일러 지원을 위해, 기존의 델파이와는 다른 새로운 델파이 컴파일러를 도입했습니다. 기존 델파이 컴파일러와의 호환성을 위해 대부분의 문법들은 하위호환되지만 델파이로 모바일 개발을 하기 위해서는 알아두어야 할 주의해야 할 부분들이 상당히 많습니다.
델파이 XE4 버전에서는 iOS 및 ARM 컴파일러 지원을 위해, 기존의 델파이와는 다른 새로운 델파이 컴파일러를 도입했습니다. 기존 델파이 컴파일러와의 호환성을 위해 대부분의 문법들은 하위호환되지만 델파이로 모바일 개발을 하기 위해서는 알아두어야 할 주의해야 할 부분들이 상당히 많습니다.
현재 엠바카데로에서 델파이 프로덕트 매니저를 맡고 있는 마르코 칸투는 문서 “The Delphi Language for Mobile Development”에서 이러한 주의점들을 간략히 설명하고 있습니다. 모바일 개발을 생각하는 델파이 개발자들에게는 아주 중요한 문서이므로, 총 4회로 나누어 이 문서를 번역해서 올립니다. 이번 글은 그중 두번째입니다.
2. 문자열 타입
문자열의 관리는 델파이 언어에서 더 중요한 변경들이 뒤따르는 영역입니다. 이 변경을 위한 몇가지 아이디어들이 있었습니다. 전통적인 델파이 모델(약간씩 다른 여러 문자열 타입들)의 단순화, 최적화 요구(일부는 모바일 플랫폼과 LLVM 플랫폼에서 요구되는 모델 때문), 그리고 델파이 언어를 다른 일반적인 프로그래밍 언어들과 맞출 필요 등입니다.
터보 파스칼 및 델파이 1 버전까지의 하위 호환성을 유지하는 일에는 많은 부담이 있었고, 새로운 개발자들은 물론 기존의 개발자들에게도 많은 도전을 제기하는 것이었습니다. 아래는 실제로 변경된 사항들로서, 각각에 대해 이해를 도와주는 코드 예제들과 마이그레이션과 향후의 크로스플랫폼 호환성 양쪽 모두를 위한 힌트들을 함께 제공합니다.
2.1: 단 하나의 문자열 타입
윈도우용 델파이의 최근 버전들에서는 기하급수적으로 문자열 타입들이 늘어났습니다. 델파이에서는 다음과 같은 문자열 타입들을 제공하고 있습니다.
- 파스칼 짧은 문자열(short string), 255 길이의 1바이트 문자들
- 참조 카운팅되는 copy-on-write AnsiString
- AnsiString에서 상속된 전용 타입들. UTF8String과 RawByteString처럼 문자열 타입 생성 메커니즘 기반
- C 언어 문자열(PChar)을 관리하기 위한 RTL 함수들
- 참조 카운트되는 copy-on-write 유니코드 문자열(UnicodeString). 현재 기본 문자열 타입이며 UTF16으로 구현
- COM 호환 와이드 문자열(WideString). UTF16 기반이지만 참조 카운트되지 않음
LLVM 기반의 새 델파이 컴파일러에는 단 하나의 문자열 타입만이 존재하며, 유니코드 문자열(UTF16)로서 델파이 XE3의 string 타입에 해당합니다(윈도우 컴파일러에서 UnicodeString 타입에 대한 별칭이기도 합니다). 하지만 이 새로운 문자열 타입은 이전과 다른 메모리 관리 모델을 사용합니다. 이 string 타입은 여전히 참조 카운트를 사용하지만, 향후 변경 불가(immutable)가 될 예정입니다. 변경 불가란 문자열이 생성된 후에는 그 내용을 변경할 수 없다는 의미입니다(해당 섹션에서 자세히 설명합니다). 요약하자면, 새 컴파일러에서 문자열은 유니코드 기반이며, 곧 변경불가(immutable)하게 될 것이며, 참조 카운트됩니다.
1바이트 문자열(ANSI 혹은 UTF8 문자열 등)을 다루어야 할 경우, 예를 들면 파일 시스템이나 소켓을 다루는 경우, 바이트의 동적 배열을 이용할 수 있습니다(“1바이트 문자열 다루기” 섹션에서 자세히 다룹니다). 먼저 핵심 기능들을 보여주는 실제 코드를 보여주고 다른 코딩 스타일을 제시할 것입니다. 이후에 새 컴파일러에서 1바이트 문자열을 다루는 방법들을 보여드릴 것입니다.
여러분이 아직 AnsiString 타입, ShortString 타입, WideString 타입, 혹은 다른 특수 목적의 문자열 타입을 사용하고 있다면, 여러분의 전체 코드를 기본 string 타입으로 변경할 것을 강력하게 권합니다. (여기서 우리는 여러분이 모바일 플랫폼으로 마이그레이션 하려고 하는 코드에 대해 말하고 있는 것입니다. 윈도우 델파이 컴파일러는 당분간은 변경되지 않습니다)
노트: “특수 목적” 문자열 타입들은 주로 바깥 세계와의 인터페이스를 위한 것이었습니다. 단적인 예가 COM 지원을 위해 도입된 WideString 타입입니다. 이런 특수 타입들은 분명히 사용하기 편리하기는 하지만, 어쨌든 바깥 세상과의 인터페이스라는 단 하나의 목적만으로 약간씩 다른 의미와 동작을 가져와 델파이 언어를 “오염”시킨 것이 사실입니다. 델파이가 다른 많은 플랫폼들로 전진하고 있는 지금, 델파이에서 이런 이런 타입들을 그대로 유지하는 것은 일을 복잡하게 만들고 혼란스럽게 할 뿐입니다. 예를 들어 윈도우가 아닌 플랫폼에서 WideString이 어떤 의미가 있을까요? 각각의 플랫폼과 인터페이스하기 위한 이런 타입들에 대해서는 언어와 컴파일러에 전용 데이터 타입들로서 가지고 있기보다는, 메소드와 연산자를 가진 레코드나 제네릭, 기타 다른 언어 기능들을 이용하여 사용자 정의 타입으로 만드는 것이 훨씬 더 명쾌한 해결책입니다.
2.2: 참조 카운트되는 문자열
과거와 마찬가지로, 델파이 문자열은 참조 카운트됩니다. 이것은 동일 문자열에 두 번째 변수를 지정하거나 문자열을 파라미터로 전달할 경우 참조 카운트가 증가된다는 뜻입니다. 모든 참조가 스코프를 벗어난 즉시 해당 문자열은 메모리에서 삭제됩니다.
대부분의 개발자들에게 이것은 개발자가 문자열의 메모리 관리에 신경 쓰지 않아도 제대로 동작한다는 뜻입니다. 저수준 구현(공지 없이 변경될 수 있습니다만)에 대해 더 자세히 이해하고 싶다면, 다음의 자세한 내용을 읽어보면 되고, 관심이 없다면 다음 섹션은 그냥 넘어가면 됩니다.
여러분이 문자열 구현의 자세한 부분까지 파고들어보고 싶다면 StringRefCount 함수로 문자열의 참조 카운트를 알아낼 수 있습니다(델파이 2009에서 추가). 아래 코드에서처럼 사용하면 됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
var str2: string; procedure TTabbedForm.btnRefCountClick(Sender: TObject); var str1: string; begin str2 := 'Hello'; Memo1.Lines.Add('Initial RefCount: ' + IntToStr(StringRefCount(str2))); str1 := str2; Memo1.Lines.Add('After assign RefCount: ' + IntToStr(StringRefCount(str2))); str2 [1] := '&'; Memo1.Lines.Add('After change RefCount: ' + IntToStr(StringRefCount(str2))); end; |
이 코드를 실행해보면, str2의 참조 카운트는 처음에는 1이었다가 str1에 대입한 후에는 2로 증가하는 것이 보일 것입니다. 그리고 str2의 값을 바꾼 후에는 다시 1이 되는데, 이것은 str2가 변경되었기 때문에 공유되었던 문자열 데이터를 str2로 복사 동작이 일어났기 때문입니다(다음 섹션에서 이 copy-on-write 메커니즘에 대해 설명). 이 코드는 윈도우, 시뮬레이터, 모바일 디바이스 어디에서 실행하든 동일한 결과(1, 2, 1)가 나옵니다.
한가지 알아둘 것은, 함수나 메소드를 사용할 때 문자열을 const 파라미터로 전달하면 그 참조 카운트는 바뀌지 않으며 해당 코드가 더 빠르게 동작하게 됩니다(겨우 몇 CPU 사이클 정도입니다만). 참조 카운트를 리턴하는 함수 StringRefCount 내부에서도 이렇게 하고 있으며, 그렇게 하지 않았다면 호출할 때마다 이 함수 자체로 인해 참조 카운트가 1만큼 증가해버릴 것입니다.
|
1 |
function StringRefCount(const S: UnicodeString): Longint; |
요약하자면, 참조 카운팅은 클래식 컴파일러와 새 컴파일러가 매우 비슷한 방식으로 동작하며, 이것은 아주 효율적인 구현입니다.
2.3: copy-on-write와 변경불가 문자열
임프 역주: 델파이 XE4 기준, 현시점에서 델파이 문자열은 변경불가(immutable)가 아닙니다. 마르코 칸투의 이 페이퍼와 엠바카데로의 공식 헬프 문서 양쪽 모두 XE4에서 문자열이 이미 변경불가라고 하기도 하고 향후 변경불가가 될 예정이라고 하기도 해서 혼란스럽게 하는데, 종합해보면 XE4 버전은 아직 변경불가 문자열이 적용되지 않은 것으로 보입니다.
기존의 문자열의 내용을 변경할 때는 달라지기 시작하는데, 이것은 문자열을 새로운 값으로 바꿔치울 때가 아니라(이런 경우엔 완전히 새로운 문자열을 갖게 됩니다) 아래 코드처럼 문자열의 요소를 변경할 때입니다(이전 섹션의 예에서도 마찬가지).
|
1 |
Str1[3] := ’x’; |
모든 델파이 컴파일러들은 copy-on-write 방식을 이용합니다. 여러분이 변경하는 문자열이 하나보다 많은 참조를 가지고 있을 경우, 일단 먼저 복사되고(관련된 문자열들의 참조 카운트가 조정됨) 이후에 수정됩니다.
노트: 이 용어에 익숙하지 않은 분들을 위해 설명하자면, “copy-on-write”는 문자열에 새 문자열 변수를 대입할 때는 복사가 일어나지 않으며, 그 내용이 변경될 때만 복사가 일어나는 것을 의미합니다. 다른 말로 하자면, 여러분이 복사 동작을 할 때 복사가 일어나는 것이 아니라 차후에 실제로 복사가 필요한 때에만 일어난다는 의미입니다. 내용 변경이 일어나지 않으면 복사 동작도 일어나지 않습니다.
새 컴파일러는 클래식 컴파일러와 매우 비슷하게 동작합니다. 문자열의 참조가 하나뿐인 경우가 아니라면 copy-on-write 메커니즘으로 구현되며, 참조가 하나뿐인 경우에는 기존의 문자열이 변경됩니다. 예를 들어 아래 코드에서는 데모 소스 코드에 있는 StrMemAddr 함수를 이용하여 실제 문자열의 메모리 위치를 보여줍니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
procedure TTabbedForm.btnCopyClick(Sender: TObject); var str3, str4: string; begin // 문자열을 정의하고 별명을 만듭니다 str3 := Copy('Hello world', 1); str4 := str3; // 메모리 위치를 보여줍니다 Memo1.Lines.Add(str3 + ' - ' + StrMemAddr(str3)); Memo1.Lines.Add(str4 + ' - ' + StrMemAddr(str4)); // 하나를 변경함 (다른 쪽은 변경하지 않음) str3 [High(str3)] := '!'; Memo1.Lines.Add(str3 + ' - ' + StrMemAddr(str3)); Memo1.Lines.Add(str4 + ' - ' + StrMemAddr(str4)); // 첫번째를 다시 변경함 str3 [5] := '!'; Memo1.Lines.Add(str3 + ' - ' + StrMemAddr(str3)); Memo1.Lines.Add(str4 + ' - ' + StrMemAddr(str4)); end; |
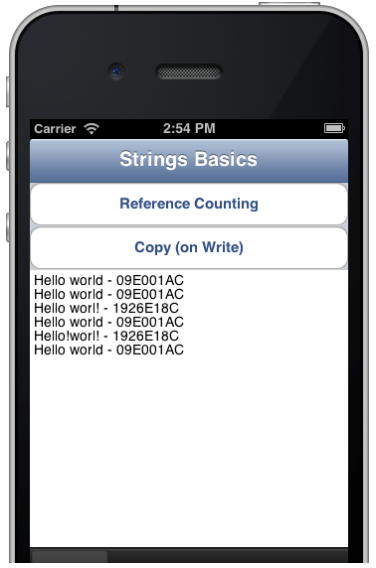
오른쪽 그림은 위 코드의 실행 결과입니다(iOS 시뮬레이터). 두 문자열 중 하나(str4)는 전혀 영향을 받지 않았으며, 다른쪽은 첫번째 쓰기 작업에서만 재할당된 것을 확인할 수 있습니다.
문자열을 변경할 수 있다면, 클래식 컴파일러와 다른 점은 무엇일까요? 현재의 문자열 조작 구현은 클래식 구현과 병행하고 있지만, 미래에는 바뀔 예정입니다. 변경불가 문자열(immutable string)은 더 나은 메모리 관리 모델을 제공합니다. 변경불가 문자열을 이용하면 문자열의 요소를 직접 변경할 수 없게 되며 더 느려지게 되지만, 반면 문자열 이어붙이기는 더 빨라집니다.
따라서 현재의 델파이 ARM 컴파일러에서는 이런 동작이 허용되고 있지만, 내부 문자열 관리 구현이 향후 바뀔 예정이며 따라서 이 동작이 허용되지 않게 될 수 있습니다.
코드가 최적화되지 않을 수도 있다거나 향후 버전에서 동작하지 않을 수도 있다는 경고(warning)를 발생시키기를 원한다면, 그 전용 경고를 켤 수 있습니다(델파이 XE3에서도 이미 클래식 컴파일러에 추가되어 있습니다). 해당 지시어는 {$WARN IMMUTABLE_STRINGS ON} 이며, 이 지시어를 지정한 상태에서 아래와 같은 코드를 사용하면,
|
1 |
str1[3] := ’w’; |
다음과 같은 경고를 받게 될 것입니다.
|
1 |
[dcc32 Warning]: W1068 Modifying strings in place may not be supported in the future |
변경불가 문자열로의 변화가 여러분의 코드에 어떤 영향을 미치게 될까요? 다음의 코드와 같은 단순한 문자열 이어붙이기의 경우 별다른 문제점이 없습니다. (이어붙이기 성능의 향상은 여러 목표들 중 하나이므로 향후로도 그럴 것입니다)
|
1 |
ShowMessage('Dear ' + LastName + ' your total is ' + IntToStr(value)); |
다른 개발환경과 달리, 우리는 문자열 이어붙이기가 훨씬 느려지거나 어떤 식으로든 금지되는 것을 기대하지 않습니다. 이슈가 될 수 있는 것은 오직 문자열의 각각의 문자를 변경하는 경우뿐입니다. 현재 R&D 팀에서 이 방향으로 진행중인 연구에서는 문자열 이어붙이기나 Format 류의 함수들 같은 일반적인 작업들을 최적화하는 방법을 찾고 있는 중입니다.
어떤 경우든, 플랫폼마다 다른 문자열 수정 및 이어붙이기의 구현 방식으로부터 자신을 보호하려면, 구현 방식과 컴파일러로부터 자유로운 문자열 생성 코드를 사용하는 편이 좋을 수 있습니다. 예를 들면 TStringBuilder 클래스가 그렇죠.
2.4: TStringBuilder 클래스의 사용
미래를 위한 주요한 옵션들 중 하나는, 여러 조각들로부터 문자열을 만들어낼 때 TStringBuilder와 같은 문자열 이어붙이기 클래스를 이용하는 것입니다. 각각의 문자나 작은 문자열들을 이어붙여 문자열을 생성한다면, 윈도우와 모바일 컴파일에서 높은 속도를 내려고 한다면 여러분의 코드를 TStringBuilder를 이용하도록 바꾸는 것이 좋은 방법입니다.
아래는 각각 일반적인 문자열 이어붙이기와 TStringBuilder 클래스를 이용하여 동일한 순환문을 작성한 예제 코드입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
const MaxLoop = 2000000; // 2백만 procedure TTabbedForm.btnConcatenateClick(Sender: TObject); var str1, str2, strFinal: string; sBuilder: TStringBuilder; I: Integer; t1, t2: TStopwatch; begin t1 := TStopwatch.StartNew; str1 := 'Hello '; str2 := 'World '; for I := 1 to MaxLoop do str1 := str1 + str2; strFinal := str1; t1.Stop; Memo2.Lines.Add('Length: ' + IntToStr(strFinal.Length)); Memo2.Lines.Add('Concatenation: ' + IntToStr(t1.ElapsedMilliseconds)); t2 := TStopwatch.StartNew; str1 := 'Hello '; str2 := 'World '; sBuilder := TStringBuilder.Create(str1, str1.Length + str2.Length * MaxLoop); try for I := 1 to MaxLoop do sBuilder.Append(str2); strFinal := sBuilder.ToString; finally sBuilder.Free; end; t2.Stop; Memo2.Lines.Add('Length: ' + IntToStr(strFinal.Length)); Memo2.Lines.Add('StringBuilder: ' + IntToStr(t2.ElapsedMilliseconds)); end; |
클래식 델파이에서는 두 방식의 실행 속도가 매우 비슷합니다(네이티브 이어붙이기가 약간 빠르게 나왔는데, 위의 코드에서 스트링빌더에는 최종 크기를 미리 할당했기 때문입니다. 미리 할당해두지 않을 경우에는 네이티브 이어붙이기가 10%에서 20% 정도 더 빠릅니다).
|
1 2 3 4 |
Length: 12000006 Concatenation: 60 (msec) Length: 12000006 StringBuilder: 61 (msec) |
iOS 시뮬레이터에서도 윈도우의 경우와 거의 비슷하며, 이것은 Mac 인텔 프로세서에 맞게 컴파일되기 때문입니다. 결과는 위의 결과와 아주 유사하게 나옵니다.
모바일 플랫폼(ARM 컴파일러와 물리적 모바일 디바이스)에서는 단순 이어붙이기는 상당히 느려질 것이 예상되며, 따라서 상당히 큰 문자열에 대해서는 TStringBuilder 만이 유일한 방법이 됩니다. 혹시 이런 말을 들어본 적이 있는 것 같다면, 아마도 마이크로소프트의 .NET 플랫폼 등의 매니지드 플랫폼들의 경우와 아주 비슷하기 때문일 것입니다.
문자열들이 재할당되어야 하는 것은 사실이지만, 메모리 매니저는 실행 속도에 대한 영향을 최소화할 수 있을 만큼 영리합니다. (지수적인 경우보다는 선형적인 경우에 더욱 그렇습니다)
|
1 2 3 4 |
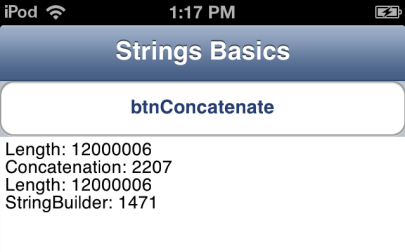
Length: 12000006 Concatenation: 2109 (msec) Length: 12000006 StringBuilder: 1228 (msec) |
위의 숫자들을 눈여겨보면, iOS ARM 디바이스에서는 TStringBuilder를 이용하는 것이 거의 두배나 빠르며, 그것도 밀리초 차이가 아닌 초 단위입니다! 아래는 물리적 디바이스에서 캡쳐한 실제 결과입니다.
다른 예제로, 문자열의 모든 요소를 스캔하여 그중 일부를 치환하는 아래의 루프를 살펴봅시다.
|
1 2 3 4 |
// 문자열을 순환하면서 조건에 따라 일부를 바꿉니다 for I := Low (str1) to High (str1) do if str1 [I] = 'a' then str1 [I] := 'A' |
변경불가 문자열이 적용된다면 위 코드는 매우 느려질 것으로 예상할 수 있을 것입니다(물론 큰 문자열의 경우). 대신 다음과 같은 코드를 사용할 수 있습니다.
|
1 2 3 4 5 6 7 8 |
// 문자열을 순환하면서 결과를 스트링빌더에 추가합니다 sBuilder := TStringBuilder.Create; for I := Low(str1) to High(str1) do if str1.Chars [I] = 'a' then sBuilder.Append('A') else sBuilder.Append(str1.Chars[I]); str1 := sBuilder.ToString; |
결과를 보면, 위의 직접 문자열 요소 치환 코드가 TStringBuilder 코드보다 10배 가량 더 빠릅니다. 사실 다음번 대문자 A를 찾고 그 앞의 문자열 부분을 복사하는 방식으로 알고리즘을 훨씬 더 최적화할 수도 있습니다. 하지만 단순무식 알고리즘(문자열의 각 요소를 일일이 검사하는)과 비교하자면, 현재의 구현에서는 앞의 단순한 코드가 더 빠릅니다. 이것은 향후로는 바뀔 수도 있는데, 변경불가 문자열의 구현이 문자열 구조에 대한 직접 변경을 금지하게 될 수도 있습니다.
노트: 다시 한번 말하지만 문자열의 내부 구현이 향후에 바뀔 수도 있다는 점을 염두해두시길 바랍니다. 다른 언어들 중에는 큰 문자열을 문자들의 하나의 연속이 아닌 문자열 조각들의 집합으로 나타내는 언어들도 있습니다. 오늘 작성한 최적화 방식이 향후에는 더 느린 구현이 될 수도 있습니다.
2.5: 0 기반 액세스
두번째 변화는, 0 기반(0-based)의 문자열에 대한 지원입니다. 이 말은, 문자열의 요소(문자)들을 대괄호와 인덱스로 액세스할 때 1이 아닌 0부터 시작한다는 것입니다. 1 기반의 문자열을 사용해온 것은 파스칼 언어의 오랜 전통으로 내려온 관례죠. 하지만 1 기반의 문자열을 사용하도록 결정했었던 이유는, 가독성(readability)의 문제이거나 요소를 세기에 더 자연스럽다거나 하기보다는, 구현상의 결정의 결과입니다. 다르게 말하면, 구현상의 필요 때문에(NULL 터미네이터를 사용하는 C와 달리 문자열의 길이를 저장하기 위해 0번째 바이트를 사용할 필요가 있었음) 규정으로 정했던 것입니다.
물론 어떤 것이 더 자연스러운지에 대해 장시간 논쟁을 벌일 수도 있지만, 대부분의 언어들은 0 기반의 문자열을 사용하고 있고, 현실적으로 델파이에서도 다른 모든 데이터 구조들도 0 기반입니다. 동적 배열, 컨테이너 클래스들, TStringList 같은 RTL 클래스들, VCL 및 FireMonkey에서 하위 요소를 가진 클래스들(메뉴 아이템, 리스트박스 아이템, 서브컨트롤…)등이 그렇죠.
이것은 델파이 언어에 대한 중요한 변경이며(새 컴파일러의 아키텍처나 모바일 지원과는 무관), 많은 코드들에 영향을 미칠 수 있기 때문에, 새로운 컴파일러 지시어 $ZEROBASEDSTRINGS으로 바꿀 수 있도록 했습니다(델파이 XE3에 이미 추가되어 있음). 델파이 XE3에서 이 지시어의 디폴트는 off이며 XE4의 모바일 컴파일러에서는 on입니다. 하지만 이것은 컴파일러 지시어이기 때문에 델파이 XE3에서 이 지시어를 켤 수도 있고(on) 반대로 모바일 컴파일러에서 (0 기반 문자열로 코드 마이그레이션을 완료할 때까지) 기존 코드가 동작하도록 하기 위해 이 지시어를 끌 수도 있습니다(off).
노트: 이에 해당하는 프로젝트 옵션 수준에서 지정할 수 있는 Extended Syntax 컴파일러 지시어도 있으며, 모든 유닛에 적용되게 됩니다(다른 로컬 세팅이 없는 경우). 이 옵션을 사용하는 경우 프로젝트에 해당하는 문자열 액세스 모델로 작성된 유닛들만 포함하도록 주의해야 합니다. 이런 경우 유닛 레벨의 로컬 세팅이 불일치를 피할 수 있도록 도와줄 수 있습니다.
이와 관련된 알아두어야 할 몇가지 중요한 사항들이 있습니다.
- 문자열의 내부 구조는 영향을 받지 않습니다. 하나의 프로젝트에서 이 지시어로 서로 다른 설정을 가진 유닛들을 섞어 쓰거나 다른 방식으로 컴파일된 함수에 문자열을 넘겨줄 수도 있습니다. 특정 소스코드 라인에서 컴파일러가 [] 표현을 어떻게 해석하든 무관하게 문자열은 그대로 문자열일 뿐입니다.
- 클래식 문자열 RTL 함수들은 기존의 방식대로 동작할 것이며, $ZEROBASEDSTRINGS가 off라면 문자열 요소에 대해 1 기반의 위치를 이용합니다. 하지만 클래식 문자열 RTL 함수들은 하위호환성을 위해 유지될 뿐이므로 그런 함수들을 멀리할 것을 권장합니다. 새로운 TStringHelper 함수들(다음에 설명합니다)을 사용할 것을 권합니다.
- 새로운 고유 타입 헬퍼 TStringHelper의 함수 셋을 사용하여 기존 코드를 마이그레이션할 것을 권장합니다. 이 헬퍼 클래스는 다음 섹션에서 자세히 설명하며 모든 컴파일러에서 0 기반의 문자열 인덱스를 사용합니다(즉 윈도우, Mac, 모바일에서 동일하게 동작합니다).
다음의 간단한 코드를 살펴봅시다.
|
1 2 3 4 5 6 7 8 9 |
procedure TForm4.Button1Click(Sender: TObject); var s: string; begin s := 'Hello'; s := s + ' foo'; s[2] := 'O'; Button1.Caption := s; end; |
델파이 XE3의 디폴트 상태에서 버튼 캡션은 “HOllo foo”가 됩니다. 하지만 이 코드의 앞에 다음의 지시어를 추가하면,
|
1 |
{$ZEROBASEDSTRINGS ON} |
버튼 캡션은 “HeOlo foo”가 됩니다. 이 경우 인덱스가 0 기반이기 때문에 문자열의 요소 2는 세번째 요소입니다. 두 컴파일러들 사이의 차이점은 다음과 같은 코드가 어떻게 해석되느냐입니다.
|
1 |
aChar := aString[2]; |
위 라인의 실제 동작은 $ZEROBASEDSTRINGS 컴파일러 지시어에 따라 결정되며, 두 컴파일러에서 디폴트 값이 다릅니다. 우리는 여러분의 코드를 새로운 모델(0 기반 문자열)로 바꿀 것을 강력히 권하며, 델파이 XE3 윈도우 및 맥 애플리케이션에 대해서도 가급적 그랬으면 합니다. 단일 문자열 인덱스 모델로 옮기면 향후 코드 가독성에 확실히 도움이 될 것입니다.
노트: 혼란의 여지가 많으므로 다시 설명합니다만, 컴파일러가 대괄호 문자 요소 액세스 연산자를 해석하는 방법은 문자열의 내부 구조와는 전혀 관련이 없다는 것을 알아두십시오. 다른 말로 하자면, 문자열은 내부적으로 이전과 완벽하게 동일하며 $ZEROBASEDSTRINGS 지시어를 켜든 끄든 전혀 다르지 않게 동작합니다.
컴파일러가 [i] 코드를 해석하는 방법만 달라진 것이며, 따라서 프로그램 내에서 서로 다른 설정으로 컴파일된 유닛 및 함수들을 섞어 쓸 수 있습니다. 함수에 0 기반의 문자열을 넘겨주는 것이 아니라 단지 특정 컴파일러 설정을 사용하는 코드로 혹은 코드로부터 문자열을 넘겨주는 것일 뿐입니다.
이것이 중요한 만큼, 아래 코드의 결과를 통해 잠재적인 이슈들을 살펴봅시다.
|
1 2 3 4 5 6 7 8 9 |
var s1: string; begin s1 := '1234567890'; ListBox1.Items.Add('Text: ' + s1); ListBox1.Items.Add('Chars[1]: ' + s1.Chars[1]); ListBox1.Items.Add('s1[1]: ' + s1[1]); ListBox1.Items.Add('IndexOf(2): ' + IntToStr(s1.IndexOf('2'))); ListBox1.Items.Add('Pos (2): ' + IntToStr(Pos('2', s1))); |
디폴트 상태에서, 시뮬레이터와 실제 디바이스에서는 윈도우 및 맥과 다른 결과가 나옵니다. 아래는 시뮬레이터의 스크린샷과 윈도우에서의 스크린샷입니다.
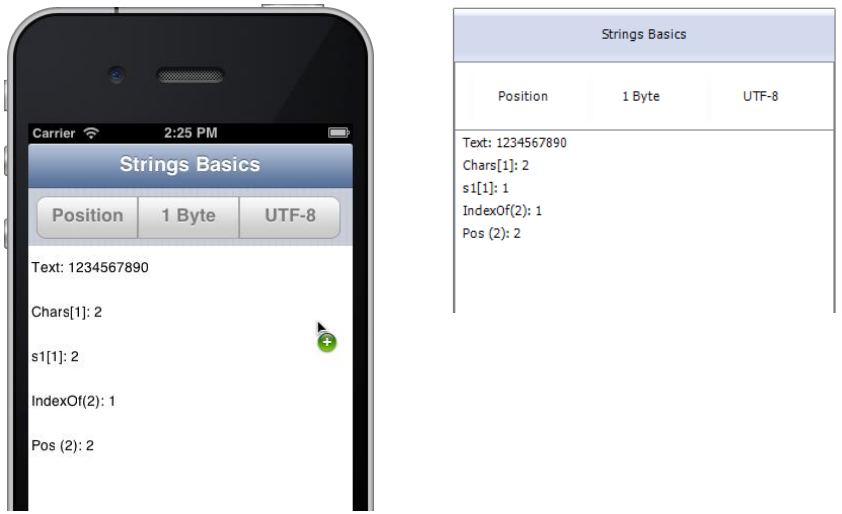
iOS에서 실행한 결과는 2/2/1/2이지만, 윈도우에서는 2/1/1/2로 나왔습니다. 유일한 차이는 두번째 값이며, 대괄호를 이용하여 직접 액세스를 한 경우입니다. 하지만 $ZEROBASEDSTRINGS 지시어를 이용하면 각 플랫폼에서의 동작을 뒤집을 수도 있습니다. 윈도우에서 $ZEROBASEDSTRINGS ON 으로 지정하면 결과는 2/2/1/2으로 나오고, iOS에서 $ZEROBASEDSTRINGS OFF 으로 지정하면 결과가 2/1/1/2으로 나옵니다.
대부분의 경우 이 문제를 피할 수 있지만, 특정 위치의 문자열 요소를 액세스할 필요가 있는 경우라면 Low() 함수(문자열의 하위 경계를 리턴)의 값을 따르는 상수를 정의할 수 있습니다.
|
1 2 |
const thirdChar = Low(string) + 2; |
이 상수의 값은 2 혹은 3이 되는데, 이를 통해 문자열의 세번째 문자를 액세스할 수 있게 됩니다. 이 상수를 정의한 후로는 세번째 문자를 다음과 같은 방법으로 액세스할 수 있습니다.
|
1 |
s1[thirdChar] |
문자열의 요소들을 반복해야 하는 경우도 비슷한 상황입니다. 예를 들면 전통적인 루프를 다음과 같은 방법으로 대체할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
var S: string; I: Integer; ch1: Char; begin // 전통적인 for 문 for I := 1 to Length(S) do use(S[I]); // 0 기반 문자열일 경우의 for 문 for I := 0 to Length(S) – 1 do use(S[I]); // for-in 루프 (델파이 2006 이후부터 가능) for ch1 in S do use (ch1); // Chars를 이용한 전통적인 for 문 (모든 컴파일러 설정에서 가능, XE3 이후 버전) for I := 0 to S.Length – 1 do use(S.Chars[I]); // Low 및 High 함수로 융통성 있는 경계값을 지정 (XE3 이후 버전에서 동작) for I := Low(S) to High(S) do use(S[I]); |
노트: Low 및 High
Low(s)는 0 기반 문자열인 경우 0을 리턴하며 1 기반 문자열에서는 1을 리턴합니다. High(s)는 0 기반 문자열인 경우에는 Length(s) – 1을 리턴하고 1 기반 문자열에서는 Length(s)를 리턴합니다. 빈 문자열이 파라미터로 전달된 경우, Low는 동일한 값을 리턴하지만 High는 0 기반 문자열에서는 -1을, 1 기반 문자열에서는 0을 리턴합니다. string 데이터 타입을 Low에 전달하면 현재의 설정을 알아낼 수 있습니다. 반면 타입을 High에 넘기는 것은 아무 의미가 없습니다.
2.6: TStringHelper 고유 타입 헬퍼 사용하기
델파이 XE3에서부터 지원하기 시작한 또다른 접근 방법은, 문자열 데이터 타입에 대한 헬퍼입니다. 이것은 XE3에서 도입된 새로운 언어 기능으로, 기존의 클래스와 레코드뿐만 아니라 네이티브 타입에도 사용자정의 메소드를 추가할 수 있게 해주는 기능입니다. 그 문법은 델파이 개발자들에게 약간 생소합니다. 다음은 사용자정의 타입을 이용한 예제입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
type TIntHelper = record helper for Integer function ToString: string; end; procedure TForm4.Button2Click(Sender: TObject); var I: Integer; begin I := 4; Button2.Caption := I.ToString; Caption := 400000.ToString; end; |
델파이 XE3에는 이 언어 기능과 함께 문자열 타입을 위한 실용적인 구현으로 TStringHelper 헬퍼가 추가되어 있습니다. TStringHelper는 SysUtils 유닛에 정의되어 있으며 Compare, Copy, IndexOf, Substring, Length, Insert, Join, Replace, Split 등등을 제공합니다. 예를 들면 아래와 같은 코드를 작성할 후 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
procedure TForm4.Button1Click(Sender: TObject); var s1: string; begin // 변수에 대해 s1 := 'Hello'; if s1.Contains('ll') then ShowMessage(s1.Substring(1).Length.ToString); // 상수에 대해 Left := 'Hello'.Length; // 메소드 체이닝 Caption := ClassName.Length.ToString; end; |
이들 모든 메소드들(Chars 인덱스 속성을 포함)은 관련 컴파일러 지시어의 값이 무엇이든 0 기반의 표기를 사용한다는 것을 알아둡시다.
노트: 위 코드에서는 메소드 체이닝을 사용하고 있습니다. 메소드 체이닝이란 해당 타입의 객체에 적용되어 자신 객체를 리턴하거나 동일 타입의 다른 객체를 리턴하도록 메소드들을 정의한 것입니다.
2.7: 1바이트 문자열 다루기
2.1 섹션에서 말했던 대로, 모든 1 바이트 문자열들은 델파이 ARM 컴파일러에서 지원되지 않습니다. 하지만 그렇다고 해서 1 바이트 문자열 데이터를 다룰 수 없다는 말은 물론 아니며, 단지 네이티브 데이터 타입으로는 할 수 없다는 뜻입니다. 실질적으로 따져보면, AnsiString, AnsiChar, PAnsiChar 등의 데이터 타입을 사용할 수 없게 됩니다.
예를 들어, 유니코드 UTF8 형식을 사용할 필요가 있다고 가정해봅시다. UTF8 파일을 읽을 경우에는 인코딩을 지원하는 TTextReader 인터페이스를 바탕으로 더 고수준의 접근 방법을 이용할 수 있습니다.
|
1 2 3 4 5 6 7 8 9 |
var filename: string; textReader: TStreamReader; begin filename := TPath.GetHomePath + PathDelim + 'Documents' + PathDelim + 'Utf8Text.txt'; textReader := TStreamReader.Create(filename, TEncoding.UTF8); while not textReader.EndOfStream do ListBox1.Items.Add(textReader.ReadLine); |
이 방식은 작성하기도 더 쉽지만 1 바이트 UTF8 문자열을 직접 다루는 동작을 숨깁니다. 다음과 같은 더 복잡한 저수준 코드를 이용하여 동일한 동작을 할 수도 있으며, 이 코드에서는 파일 읽기의 내부 동작이 나타납니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
var fileStream: TFileStream; byteArray: TArray<Byte>; strUni: string; strList: TStringList; begin ... fileStream := TFileStream.Create(filename, fmOpenRead); SetLength(byteArray, fileStream.Size); fileStream.Read(byteArray[0], fileStream.Size); strUni := TEncoding.UTF8.GetString(byteArray); strList := TStringList.Create; strList.Text := strUni; ListBox1.Items.AddStrings(strList); |
이런 데이터 구조를 메모리에서 다루기를 원하는 경우가 있을 수도 있겠습니다(예를 들면 직접 데이터 조작을 하기 위해 저수준 함수 호출을 하는 경우). 이런 경우 우리는 바이트의 동적 배열을 사용할 것을 강력히 권합니다. 배열을 자신만의 데이터 구조로 감싸서 현재의 동작 방식과 비슷하게 보이도록 할 수도 있습니다.
|
1 2 3 4 5 6 7 8 9 |
type UTF8String = record private InternalData: TBytes; public class operator Implicit(s: string): UTF8String; class operator Implicit(us: UTF8String): string; class operator Add(us1, us2: UTF8String): UTF8String; end; |
이 레코드는 연산자 오버로딩을 이용하며, TUTF8Encoding 클래스를 기반으로 구현할 수 있습니다. TUTF8Encoding 클래스는 UTF8 바이트 배열을 UTF16 문자열로, 혹은 그 반대로 변환하는 준비된 메소드들을 제공합니다.
이런 레코드를 작성하면 내장된 UTF8String 타입이 존재하지 않는 델파이 ARM 컴파일러에서도 다음과 같은 코드를 컴파일할 수 있게 됩니다.
|
1 2 3 4 5 6 |
var strU: UTF8String; begin strU := 'Hello'; strU := strU + string(' ăąāäâå'); ShowMessage(strU); |